文本隐写笔记
Base64 隐写
当存在
=的时候,最后一个非=字符将会有两位与解码无关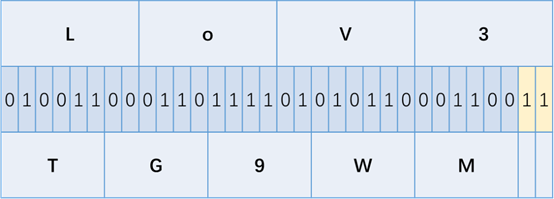
当存在
==的时候,最后一个非=字符将会有四位与解码无关
故例如 aGU= 和 aGW=
的解码结果是一样的,但我们可以在里面隐藏两位数据;aA== 和
aK== 的解码结果是一样的,但我们可以在里面隐藏四位数据。
故有以下隐写和提取代码:
1 | def extract(bases: typing.Sequence[str], needBin: bool=False): |
Brainfuck
Brainfuck 是一款极简的深奥语言(eco-language),特征是它由
> < + - . , [ ] 八种符号组成代码,并且开头可能会出现
+++++ +++++[ 的代码。
需要注意的是对于不同长度的明文,可能会出现不同的头。如果代码头不存在时,需要自己尝试添加
+ 爆破。
Brainfuck 维护一个栈,类似图灵机的纸带,以下是指令及其含义
| 字符 | 含义 |
|---|---|
| > | 指针加一 |
| < | 指针减一 |
| + | 指针指向的字节的值加一 |
| - | 指针指向的字节的值减一 |
| . | 输出指针指向的单元内容(ASCⅡ码) |
| , | 输入内容到指针指向的单元(ASCⅡ码) |
| [ | 如果指针指向的单元值为零,向后跳转到对应的]指令的次一指令处 |
| ] | 如果指针指向的单元值不为零,向前跳转到对应的[指令的次一指令处 |
需要注意的是,有可能在输出的时候栈不平衡(字面意思指
> 指令与 <
指令数不相等),可能在栈中隐藏未输出的信息,可以添加指令
<. 或 >. 来输出栈全部信息。
1 | code + '<.' * (code.count('>') - code.count('<')) |
emoji 加密
有关 emoji 表情的加密有很多,需要一个一个尝试。
- Base100
- emoji-aes
- Codemoji 与暴力破解工具
- 奇怪工具箱的 Emoji 加密
Malbolge
据称是世界上最难的五种编程语言之一,特点是由 33-126 ASCII 范围内的字符组成代码,是一个三元虚拟机语言。
在线编译执行网站:https://www.tutorialspoint.com/execute_malbolge_online.php 和 https://malbolge.doleczek.pl/
OCR
有的时候图片所包含的文本太长,手读困难且短时间内无法快速识别,我们就需要使用到 OCR(光学字符识别),可以帮我们有效提高时间效率。
但需要注意的是,OCR 往往只对印刷体和计算机字体有较高的识别率,但对手写体等可能并不能很好的识别,所以最好需要进行检查和纠错。
可以使用 https://ocr.wdku.net/ 进行识别,免费支持精确的文字识别(相对来说误差率会更低一些)。
PYC 隐写
PYC 隐写即剑龙隐写(Stegosaurus),因为该软件的名字翻译过来就是剑龙。
在 https://github.com/AngelKitty/stegosaurus 可以直接安装使用此软件。(建议直接使用 Release 版本)
内有 Python 脚本和编译好的 Linux 软件,按个人喜好使用。
使用方式为
1 | ./stegosaurus -x xxx.pyc |
SNOW 隐写
SNOW 是 the Steganographic Nature Of Whitespace 的简写。
SNOW 用于通过在行尾附加空格和制表符来隐藏 ASCII 文本中的消息,所以当看到大量非同寻常的空格或者制表符时,可以考虑是 SNOW 隐写。
同时 SNOW 隐写主要运用在 HTML 文件(网页)中,所以 SNOW 隐写又被称为 HTML 隐写。
使用以下指令提取消息:
1 | SNOW.EXE -C -p password infile outfile |
其中 -p 后面跟着密码字符串,可以包含空格等字符 (例如
-p 'Hello Wolrd')。
需要注意的是,infile 必须在 outfile
前,如果不填 infile 选项,则默认从标准输入中获得;如果不填
outfile 选项,则默认输出到标准输出中。
更多信息可以参考本博客。
sce10
ASP/VBS 代码加密,官方提供的加密工具为 sce10,一定存在字符串
VBScript.Encode。
特点是一般以 #@~
这几个字符开头,并且里面多次出现,并且不对中文字符编码。
比较出名的解密软件是 scrdec18.exe。
Twitter Secret Messages (半角全角字符隐写)
一开始是作为隐藏推特文章的一个文本隐写手段,它会将半角字母转换为全角字母(Unicode 同形字母),特点就是一段话会看起来十分的奇怪:
1 | Wow!! What a wonderful day !!! І wish I could eхtend this day as |

我们可以使用在线加解密网站对这样的字符串进行解密,只需将对应的字符串粘贴在 Decode 区域中的 Tweet 文本框中即可:

Twin-Hex
加密结果如下所示,首先两个两个字符进行十六进制加密,随后再进行base36加密,所以特点是base36解密后只会有数字。
1 | 58s4vb6sx6786pr6nt53n6w0 |
Vigenere
维吉尼亚的词频分析求解十分常见,这里仅给出在线求解网站,各种网站在分析性能上无孰优孰劣之分。
- https://www.guballa.de/vigenere-solver
- https://quipqiup.com/
- https://www.dcode.fr/chiffre-vigenere
Whitespace
WhiteSpace 是一种只用空白字符(空格,TAB和回车)编程的语言,而其它可见字符统统会被当做注释对待。
特点就是可以看到大量的空格和TAB相连的情况,具体可以参考此博客。
我们可以使用 https://vii5ard.github.io/whitespace/ 进行运行和编辑 WhiteSpace 程序。
wbStego
wbStego 支持 TXT,HTML,XML 和 PDF 文件。
HTML,TXT,XML 的隐写会出现大量空白字符,类似 SNOW 隐写。
PDF 的隐写会出现未知流 <stream>。
Word 隐藏文字
Word 有许多排版方式,其中有一种字体效果是隐藏。
对于这种情况可以直接使用 ctrl + A 快捷键选取所有文本,然后右键选择字体,再将隐藏效果关闭。
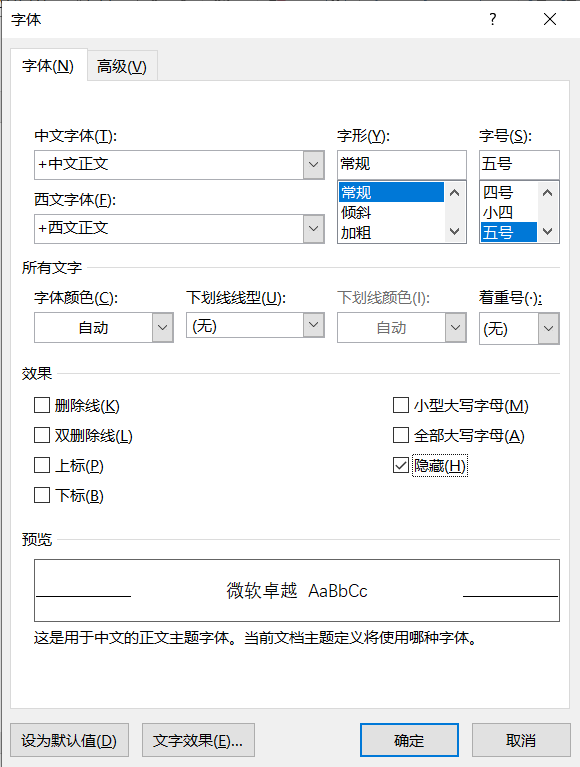
同时如果想要准确判断是否存在隐藏文字,可以点击文件-信息-检查文档。
这个功能可以检查是否存在因为设置导致的不可见对象或者隐藏文字。
Zero-Width 隐写(0宽字符隐写)
零宽度字符是一些不可见的,不可打印的字符。它们存在于页面中主要用于调整字符的显示格式。
使用 vim 可以直接查看到这些特殊的 0 宽字符,例如
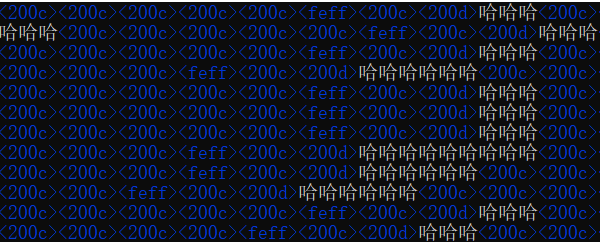
可以使用在线加解密网站对0宽字符隐写进行解密。
将加密文本放在右侧,点击 Decode
即可将文本和加密信息分离:
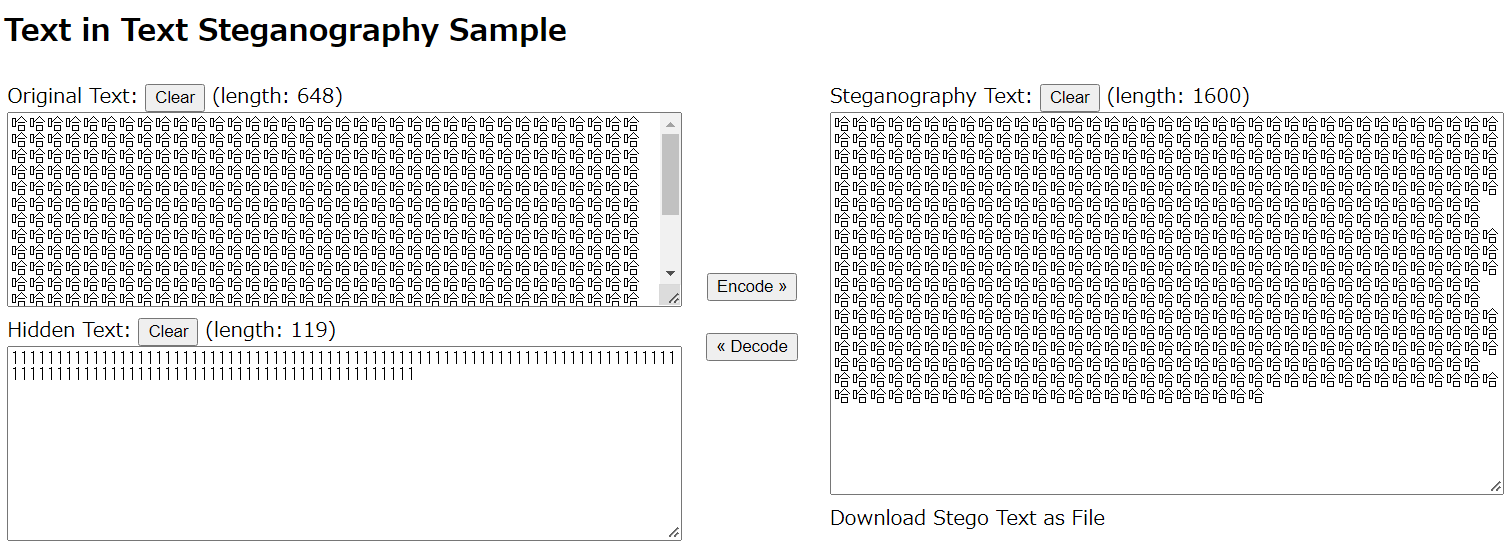
该网站可以自由选择加解密参数,通常只用选择文本中存在的零宽字符。但缺点是该网站对零宽字符的支持过少。
还可以使用网站:https://yuanfux.github.io/zero-width-web/
该网站的优势是支持所有的零宽字符,但缺点是无法自由选择你想要的零宽字符。
原理是对每个字符的每两位用零宽字符转码,比如说最经典的单表替换是
1 | zero_character_mapping = { |
330k 所写的零宽隐写每个字符使用 Unicode 表示,一个字符用十六位、八个零宽字符表示,相当于 base4。
yuanfux 的零宽隐写相当于 base5。
加盐对称加密
特征点是 Base64 开头是 U2FsdGVk,即
Salted,翻译过来后,除去 Salted__ 的字样后 8
个字节是记录在密文中的盐(Salt),这样仅需口令(passphrase)即可解密密文。
可以使用在线网站逐一尝试,如果不是主流加密还需使用
openssl 软件手动解密。
词频隐写
将关键信息转换成冗余字符后打乱顺序,用词频顺序进行解密,一般来说会利用
Python 的 collections.Counter
进行词频统计,一个简单的题解可能是这样的:
1 | from collections import Counter |
盲文
盲文各个国家、各个地区标准不一样,同时需要注意大小写问题。
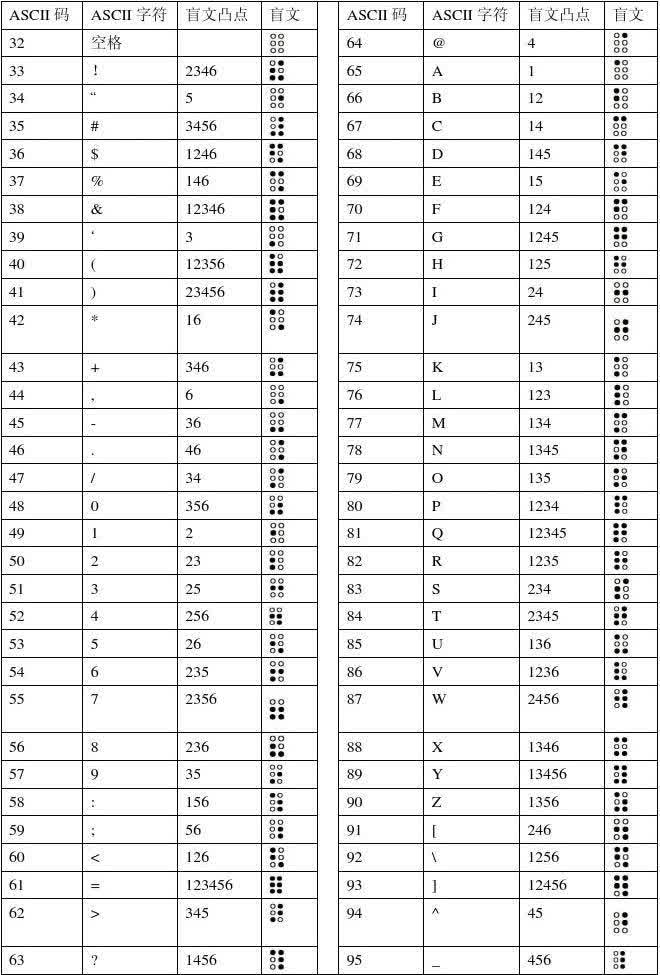
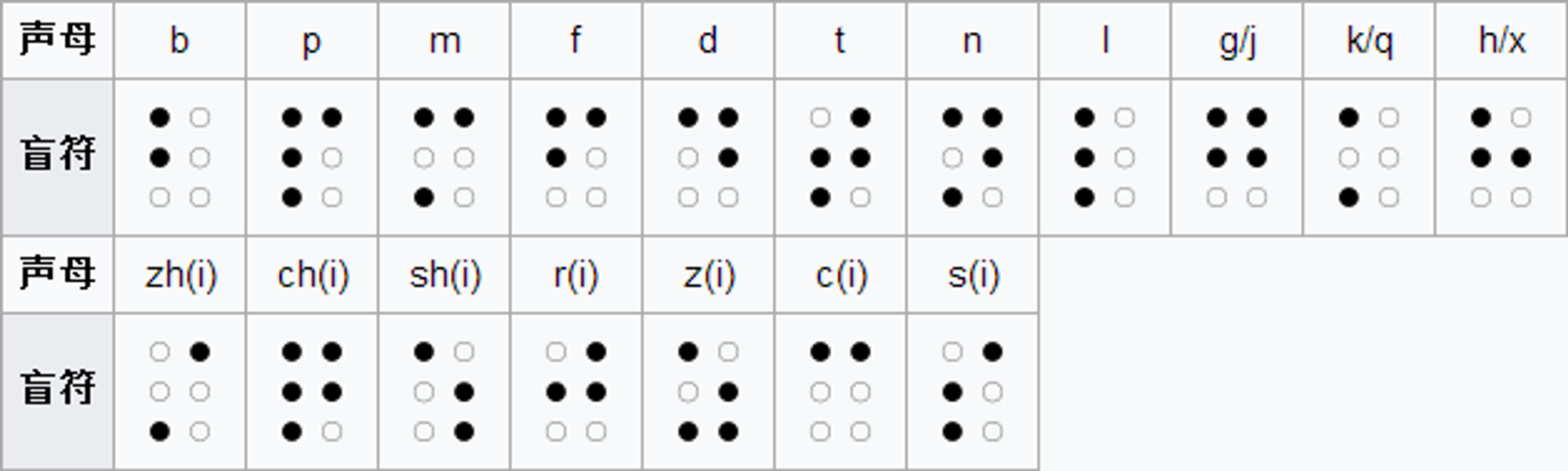
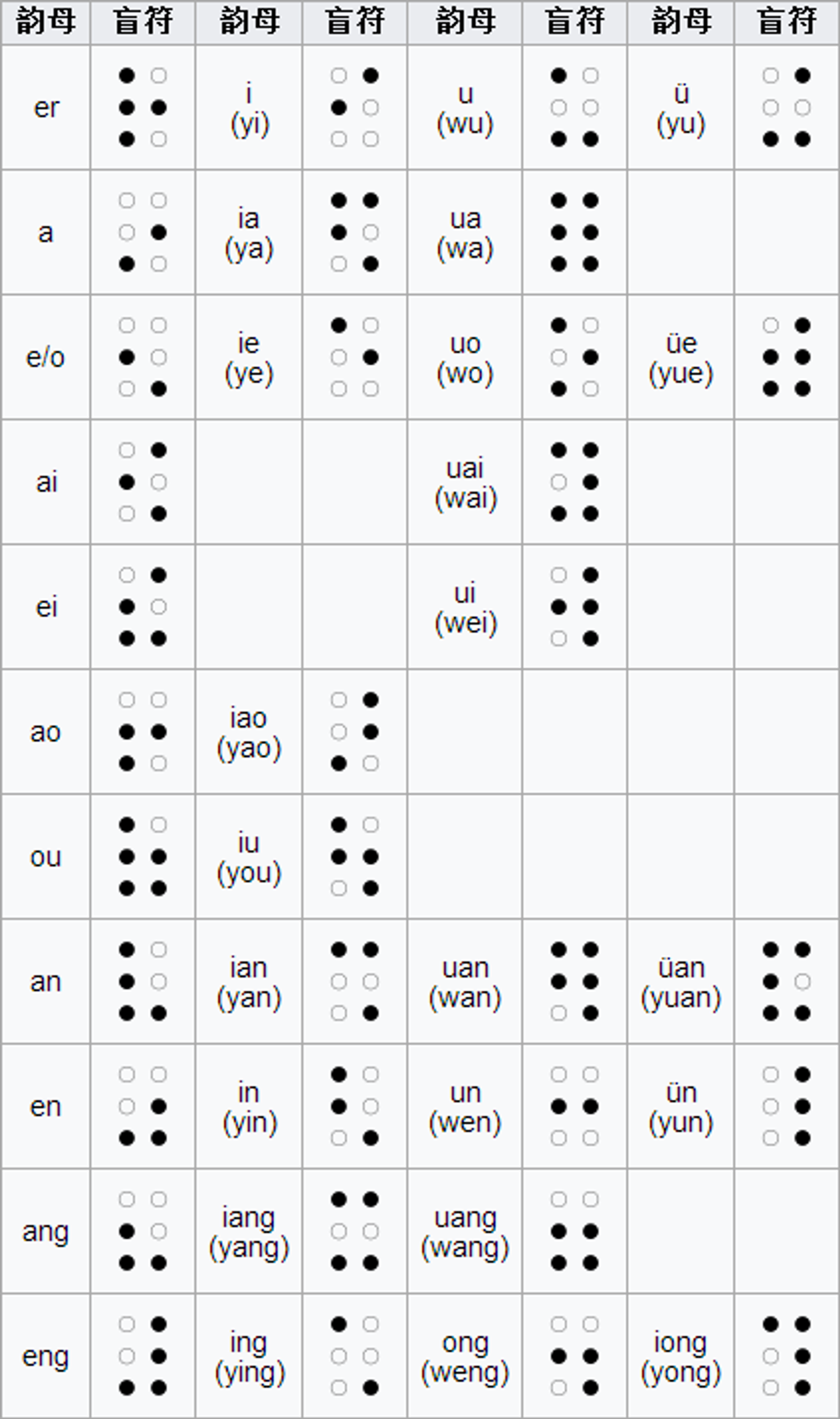
各种奇怪编码集合
- 中文电码
- AAEncode:JavaScript 代码转颜文字
- JJEncode:JavaScript 编码混淆
- PPEncode:Perl 编码混淆
- RREncode:Ruby 编码混淆
- UUEncode:可以看作 Base64 子集
- XXEncode:可以看作 Base64 子集
- JSFuck:http://www.liminba.com/tool/jsfuckdecode/,http://codertab.com/JsUnFuck,http://www.hiencode.com/jsfuck.html,JavaScript 代码混淆
- 中文摩斯电码
- BubbleBabble:胡言乱语,特征是五个五个字符一组
xisel-fanel-pivol-ninul-fuxax - Handycode:数字编码,特征是重复数字和空格
77 7777 3 9999 999 999 3 7777 - 千千秀字的各种字符加密:https://www.qqxiuzi.cn/bianma/wenbenjiami.php
- 一个工具箱的各种加密解密:http://www.atoolbox.net/Category.php?Id=27
- 盲文加密(千千秀字和一个工具箱):原理是 Base64
流量分析
WinRM 数据包
Ping 流量包
Ping 流量可以夹杂有效数据。
正常的 Ping 包应该带有的是有序的填充数据,而非无序的(相对而言)。
错误的 TCP 包
错误的 TCP 包可以夹杂有效数据(或者是其他未被使用的 TCP 包),因为一个有效流量包中的 TCP 包不应该出现大规模丢包、错包。
Wireshark 标记为黑色。
例如可以通过发送 Sequence Number 不对的 TCP 包,通过 Sequence Number 来传输数据,此时会出现同一个端口发送了大量错包,导致 Wireshark 识别 TCP 的 Sequence Number 顺序不对。
空白字符隐写
利用空白字符进行隐写的手段很多,目前已经见过的有:
- 制表符代表摩斯电码中的长码
(
-),空格代表摩斯电码中的短码 (.) - 长空白代表二进制中的 1,短空白代表莫斯电码中的 0